Du vet hur betydelsefullt ett väl fungerande nätverk är och hur allvarligt ett nätverksavbrott är för din organisation. Men nätverksproblem är oundvikliga. Verksamheten är beroendet av nätverket för att möta de ständigt föränderliga kraven från användare och interna resurser utsätter nätverket för prövningar.
Detta gör nätverk sårbara för vanliga IT-problem som oplanerade, plötsliga driftstopp, högt resursutnyttjande och hårdvarufel.
Så att möta flaskhalsar är inte nytt för en nätverksadministratör men nyckeln ligger i hur väl du analyserar hur problem uppstår.
Två fokusområden för att minska nätverksproblem
- Mean time to repair (MTTR): Det är ett mått på den genomsnittliga tid det tar att reparera ett fel och återställa nätverket. Ett högt MTTR-värde kan skada din verksamhet ekonomiskt och innebära straffavgifter för att SLA inte efterlevs. Så att ha ett effektivt, robust system för att hantera fel i nätverket är avgörande.
- Att hitta grundorsaken: Nätverk är komplicerade system som består av en mängd olika enheter och gränssnitt och detta gör det till en stor utmaning för nätverksadministratörer att hitta grundorsaken till nätverksflaskhalsar. Tid som förflutit för att lokalisera nätverksproblem innebär att ditt nätverks MTTR ständigt ökar vilket kan påverka din verksamhet på sikt.
Root Cause Analysis i övervakning
Problemidentifiering är den största utmaningen som du står inför när du försöker förbättra MTTR. Att bibehålla en låg MTTR kommer att behålla kundernas förtroende och skydda din verksamhet från kostsamma störningar.
Root Cause Analysis (RCA), eller grundorsaksanalys som det heter på svenska, gör det möjligt för dig att djupgående analysera nätverksprestanda. Med RCA kan du få omfattande insyn i nätverksövervakningsdata för alla dina enheter, gränssnitt och webbadresser i en centraliserad konsol.
Med fullständig insyn i den relevanta övervakningsinformationen minskar tiden det tar att analysera prestanda och begränsa grundorsaken avsevärt, vilket resulterar i ett lägre totalt MTTR-värde.
Viktiga funktioner i Root Cause Analysis
Jämför nätverksmonitorer grafiskt
Dra och släpp prestandastatistiken för dina valda enheter, interface eller webbadresser så bygger RCA automatiskt ett diagram med prestandakurvor. Jämför flera enheters prestanda på ett enda mätvärde eller flera mätvärden för en enda enhet, allt i en vy.
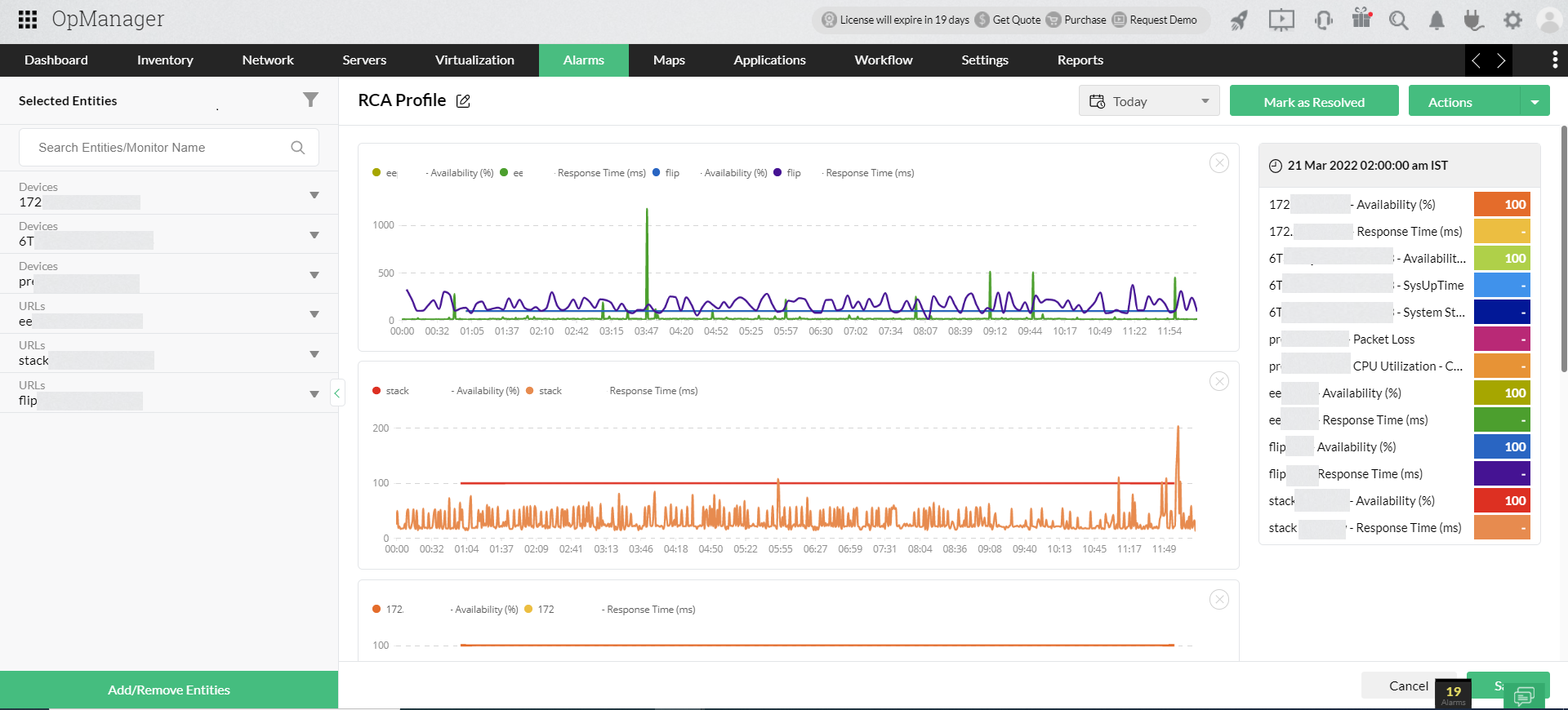
Spela in dina tolkningar
Att hitta grundorsaken handlar om att samla in nödvändiga övervakningsdata, jämföra och analysera dem på djupet och slutligen registrera dina tolkningar. Med hjälp av anteckningsalternativet kan du spela in dina resultat och lägga till hur problemet lösts när du har hittat grundorsaken. När du vill stoppa din analys halvvägs kan du spela in dina tolkningar fram till den punkten och spara dem.
När du kommer tillbaka kan du fortsätta från den punkt där du slutade. Detta hjälper också oerhört mycket när flera team-medlemmar samarbetar för att hitta grundorsaken. Till exempel kan en nätverksadministratör utföra RCA och registrera sina resultat och senare kan exempelvis en driftchef läsa anteckningarna och fatta datadrivna beslut om konfigurationsändringar i nätverket.
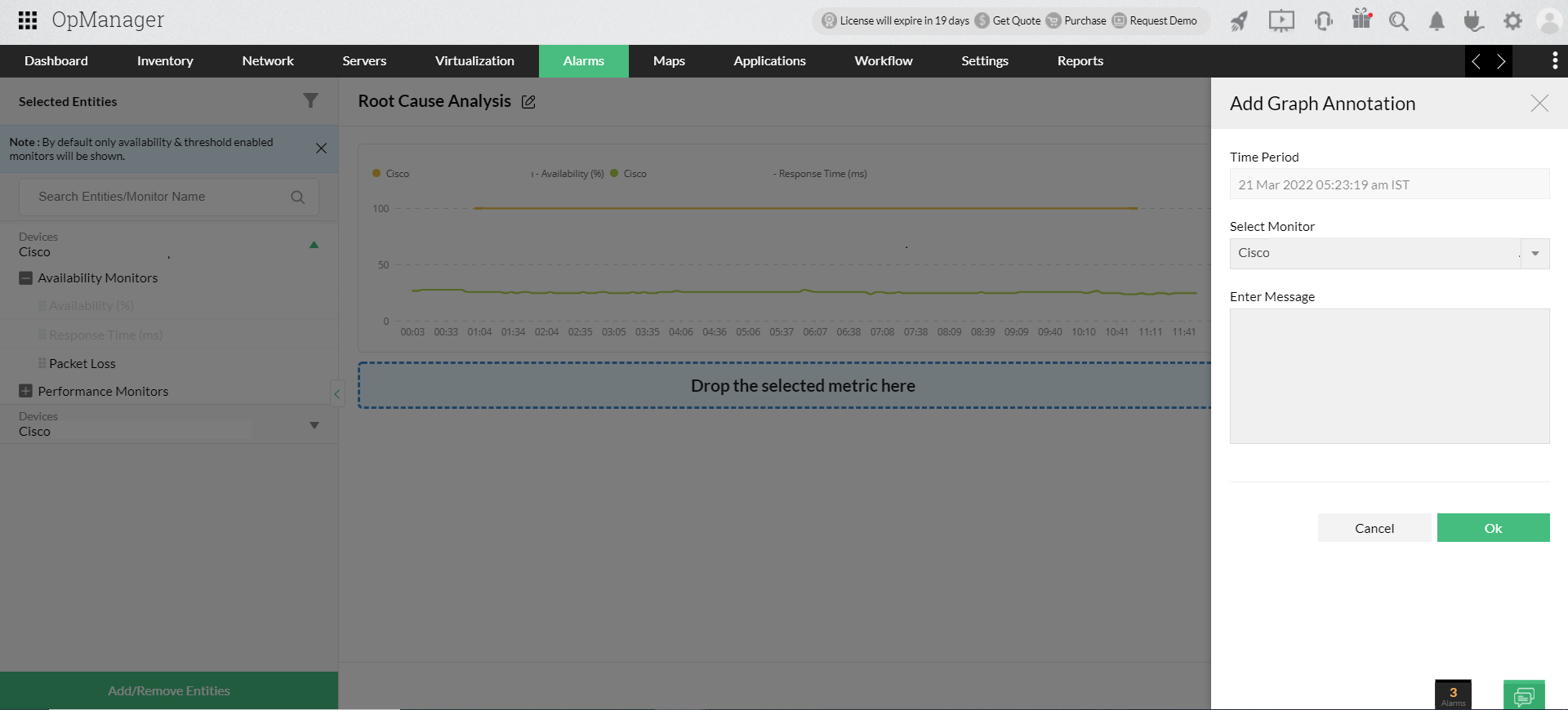
Utför RCA för grupper
Det här alternativet är användbart för att analysera prestandan för en uppsättning enheter eller gränssnitt tillsammans. Till exempel när ett visst nätverk på en specifik webbplats går ner kan du välja nätverket (gruppen) som automatiskt populerar enheterna som är specifika för den gruppen så du kan börja analysera prestandaproblemen direkt.
Hur förenklar RCA nätverksövervakning?
Utan RCA är det väldigt svårt att identifiera grundorsaken till problemet. Tänk dig till exempel att ett larm utlöses när en router i ditt nätverk går ner. Du måste gå igenom larmdata och även besöka enhetens ögonblicksbild för att förstå mer om problemet.
Den här metoden kan tyckas vara enkel när du behöver utföra root cause analysis för endast en enhet. Men vad händer om flera enheter i ditt nätverk går ner och detta resulterar i ett fullständigt nätverksavbrott?
Med RCA kan du se prestandagrafer för olika övervakade enheter i en centraliserad modul och jämföra dem tillsammans i en gemensam vy. Med en stor mängd information på din skärm blir analys av prestanda och lokalisering av grundorsaken mycket enklare.

Ett praktiskt användningsfall
Låt oss säga att användare rapporterar en långsam laddningshastighet när de ska använda en app. För att lösa problemet helt måste du hitta den verkliga orsaken och sedan vidta korrigerande åtgärder.
- Först kan du spåra CPU:n och minnesutnyttjandet av din applikationsserver för att förstå om den långsamma laddningshastigheten beror på en serveröverbelastning. Om du utesluter denna möjlighet kan du analysera nästa uppsättning möjliga orsaker.
- En långsam laddningshastighet kan också uppstå när din app-server väntar på lagringsenheten som innehåller ditt filsystem. Du kan kontrollera IOPS (Input / Output Per Second), latens, genomströmning och användning av din lagringsenhet för att förstå om problemet beror på en underpresterande och överutnyttjad lagringsenhet.
- Ibland kan den långsamma laddningshastigheten också uppstå på grund av bandbreddsproblem i gränssnitten som ansluter servern och din lagringsmiljö. Övervakning av gränssnitts Rx interface- och Tx interface-måtten hjälper dig att lokalisera eventuella flaskhalsar.
Så när du stöter på ett komplext scenario som det som diskuterades ovan, måste du jämföra prestanda för flera nätverkskomponenter. RCA tillhandahåller plattformen för att samla all data i en enda vy, analysera den, utesluta möjligheter och begränsa den exakta grundorsaken till problemet på kortare tid.
Vill du komma igång med Root Cause Analysis (RCA)?
RCA är en funktion i OpManager och du kan ladda ner och testa lösningen i 30-dagar. Vi på Inuit erbjuder personlig online demo med våra specialister som kan svara på alla dina relaterade frågor.
